OER – Connected Lecturers
Das Projekt adressierte die geringe Nachnutzung von Open Educational Resources in der sächsischen Hochschullandschaft, die auf mangelnde Auffindbarkeit und fehlende Metadaten zurückzuführen ist. Von ca. 14.000 OER-Einzeldateien in OPAL wiesen weniger als 3% grundlegende Metainformationen auf.
Durch Einsatz Künstlicher Intelligenz wurde eine vollautomatische Verarbeitungspipeline entwickelt: Nach Aggregation und Filterung textbasierter Formate (PDF, PPTX, DOCX) erfolgte die Metadatenextraktion mittels Large Language Model (Llama 3.1:70b) und Retrieval-Augmented Generation. Für jedes der 4.655 finalen Dokumente wurden Autor:innen, Titel, Institution, Zusammenfassung, Materialtyp und 15 Keywords extrahiert sowie eine DDC-Klassifikation vorgenommen. Die Qualitätssicherung erfolgte durch GND-Abgleich über die LOBID-API.
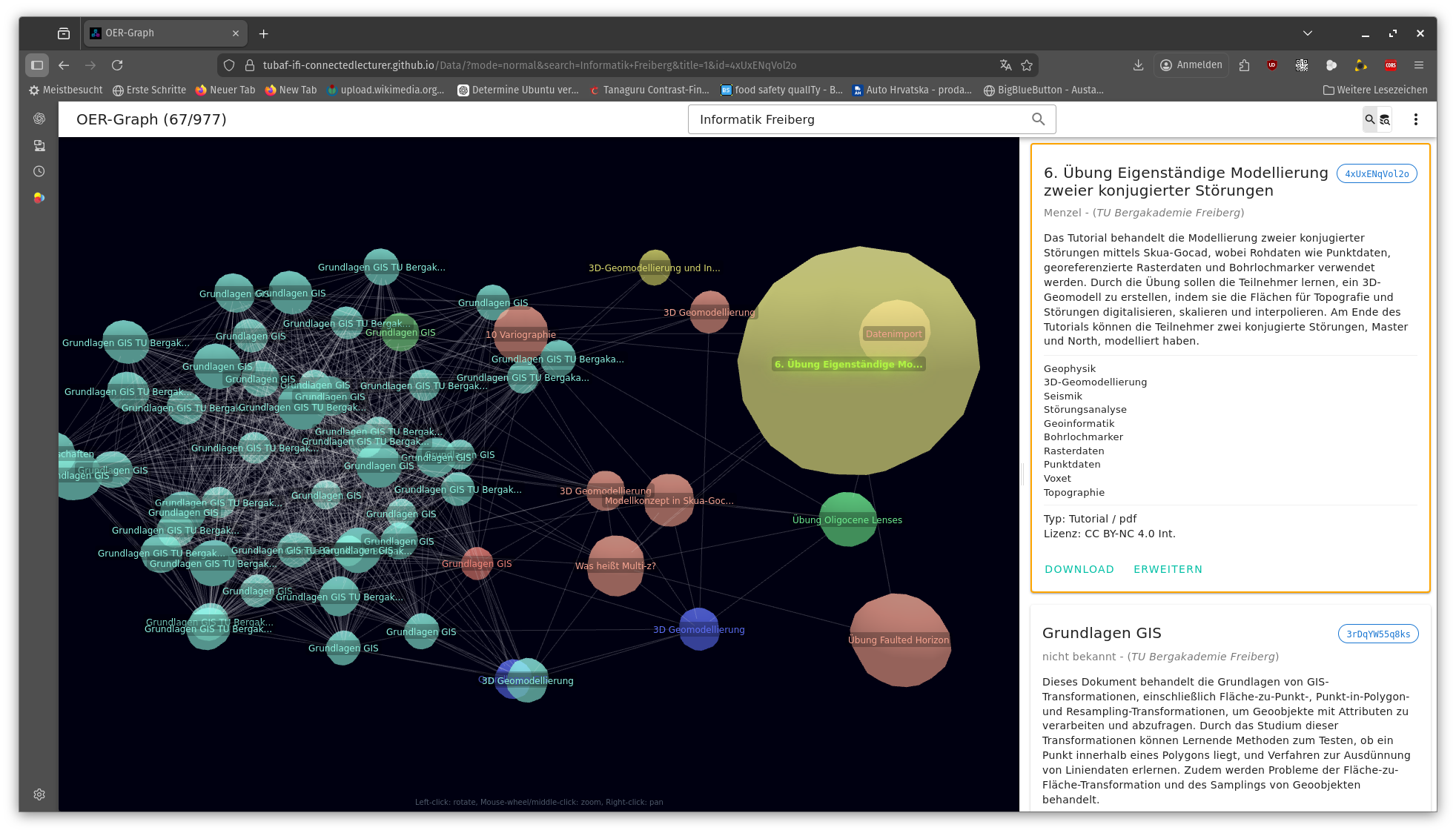
Zur Identifikation thematisch verwandter Materialien wurden fünf Ähnlichkeitsmetriken implementiert und evaluiert (vektorbasiert, MinHash, TF-IDF, mengenbasiert, hierarchisch). Die Ergebnisse werden in einer Progressive Web App als interaktiver 3D-Graph mit 4.548 Knoten und 50.628 Kanten visualisiert, durchsuchbar und offline-fähig.
Die vollständige Pipeline ist Open Source auf GitHub verfügbar und wurde erfolgreich auf weitere OER-Repositories übertragen (LiaScript, Universität Leipzig). Eine Integration in OPAL zur automatischen Metadatenextraktion beim Upload ist in Vorbereitung.
Details
Projektträger
Sächsisches Staatsministerium für Wissenschaft Kultur und Tourismus (SMWK)
Lessons Learned
Was lief gut im Projektverlauf?
- Übertragbarkeit: Die modulare Pipeline-Architektur mit JSON-Konfiguration ermöglichte erfolgreiche Anwendung auf weitere OER-Repositories (LiaScript, Universität Leipzig) mit minimalen Anpassungen
- Interdisziplinäre Kooperationen: Regelmäßiger Austausch mit der Universitätsbibliothek Freiberg und Teilnahme an DNB-Weiterbildungen brachten wertvolle Impulse für bibliothekarische Erschließungsstandards.
Welche Herausforderungen ergaben sich bei der Projektdurchführung?
- Heterogenität der Materialien: Der OER-Bestand in OPAL erwies sich als sehr heterogen – von professionellen Vorlesungsskripten über studentische Hausaufgaben bis zu handschriftlichen Notizen. Dies erschwerte eine einheitliche Qualitätsbewertung.
- Rechenaufwand: Die lokale LLM-Verarbeitung von 4.655 Dokumenten nahm ca. 62 Stunden auf einer High-End-GPU in Anspruch. Für größere Datenbestände oder häufigere Updates wäre eine Optimierung erforderlich.
Was würden Sie aus Ihren Erfahrungen heraus für ähnlich angelegte Projekte empfehlen?
- Frühe Einbindung der Zielgruppe: Die fehlende systematische Nutzerevaluation ist eine Lücke. Künftige Projekte sollten von Beginn an regelmäßige Feedback-Schleifen mit Lehrenden einplanen.
- Inkrementelle Integration: Statt sofortiger Vollintegration in bestehende Systeme (wie OPAL) ist ein schrittweiser Ansatz sinnvoll: Erst Standalone-Prototyp, dann Schnittstellen, schließlich vollständige Integration.
Weitere „Lessons-Learned“:
- GND-Integration wertvoll: Der Abgleich mit der Gemeinsamen Normdatei über die LOBID-API verbesserte die Keyword-Qualität signifikant und sollte Standard bei bibliothekarischer Erschließung werden.
-Kooperation DNB und Bibliotheken essenziell: Der Austausch mit der Deutschen Nationalbibliothek und Universitätsbibliotheken brachte methodische Impulse, die im Projekt sonst gefehlt hätten.
Nachnutzungsmöglichkeiten
- OPAL-Integration (2026): Mit verbliebenen Restmitteln wurde eine Beauftragung der BPS GmbH Chemnitz initiiert, um die Metadatenextraktions-Pipeline als Service in OPAL zu integrieren. Der Service wird beim Upload neuer PDF-Dokumente automatisch Metadatenvorschläge generieren.
- Evaluationsstudie: Die fehlende systematische Nutzerbefragung soll im Rahmen der anstehenden dritten Publikation nachgeholt werden.
- Webdienst für Einzelmaterialien: Als kurzfristige Alternative zur vollständigen OPAL-Integration wird ein Webdienst bereitgestellt, mit dem Lehrende eigene Materialien auf ähnliche Dokumente prüfen können.
Studierendenzentrierung
Für die Studierenden eröffnet sich ein umfassende Recherchemöglichkeit im Bestand der sächsischen OER Materialien. Passgenaue Inhalte von anderen Lehrenden können rasch identifiziert werden.
Weitere Informationen
Projektzeitraum: 01.04.2024 bis 30.09.2025
Produkt
Verbesserte Metadatenerfassung in OPAL für pdf (ab 2026)
Produkt
Verbesserte Metadatenerfassung in OPAL für pdf (ab 2026)
www.tubaf-ifi-connectedlecturer.github.io/Data/?mode=normal&search=Bergakademie
Generelles
Die gesamte Implementierung ist unter
https://github.com/TUBAF-IFI-ConnectedLecturer
abrufbar. Dies umfasst:
- Data_aggregation: Pipeline-Implementierung
- Data_analysis: Auswertungsskripte
- Data: Visualisierungs-App und Datenbank
- Presentations: Vortragsfolien
Die im Rahmen des Projektes vorgenommenen Entwicklungen sind Gegenstand von 2 Veröffentlichungen, die sich gegenwärtig im Reviewprozess befinden.
Kontakt
Prof. Dr. Sebastian Zug
TU Bergakademie
sebastian.zug@informatik.tu-freiberg.de
03731 39-2568